
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- javascript
- 명령어
- Java
- python 멀티프로세싱
- 가상 환경
- python easyocr 학습
- python pool
- 자바스크립트
- conda
- python multiprocessing
- multiprocessing
- 함수
- 파이썬 기초
- easyocr 기존 모델 학습
- 설치
- 기초
- 파이썬 멀티프로세싱
- python
- easyocr 기존 모델
- EasyOCR
- react
- Anaconda
- python 기초
- 리액트
- 기존 모델 학습
- 파이썬 학습 테스트
- 파이썬 pool
- python 학습
- 자료형
- 파이썬
- Today
- Total
귀찮아서가끔하는블로그
[Python] easyocr 사용자 모델 학습하기 - 기존 모델 학습 및 테스트 본문
지난 포스팅에서는 학습한 모델을 테스트하는 법을 다뤄보았다.
이번 포스팅에서는 이미 학습된 기존 모델을 학습하고 테스트하는 법을 다뤄보도록 할 것이다.
1. 기존 모델 다운로드 받기
jaided.ai/easyocr/modelhub/
2. 기존 모델 설정 확인하기
EasyOCR의 config.py 확인
* 해당 포스팅에서는 korean_g2 모델을 사용한다.
3. 기존 모델 학습하기
deep-text-recognition-benchmark 경로에서 'train.py' 실행
* --input_channel, --output_channel, hidden_size 옵션은 EasyOCR 프로젝트 모델 설정을 맞춰주기 위함이다.
python train.py
--train_data training/kordata
--valid_data validation/kordata
--select_data / --batch_ratio 1
--Transformation None
--FeatureExtraction VGG
--SequenceModeling BiLSTM
--Prediction CTC
--input_channel 1
--output_channel 256
--hidden_size 256
--saved_model pre_trained_model/korean_g2.pth
--workers 0
--FT에러 발생 (torch.Size)
검색해보니 기존 모델과 학습할 모델의 size가 맞지 않아 발생한 에러라고 한다.
No Transformation module specified
model input parameters 32 100 20 1 256 256 1011 25 None VGG BiLSTM CTC
loading pretrained model from pre_trained_model/korean_g2.pth
Traceback (most recent call last):
File "train.py", line 320, in <module>
train(opt)
File "train.py", line 85, in train
model.load_state_dict(torch.load(opt.saved_model), strict=False)
File "C:\Users\SolutionDev\anaconda3\envs\sung_python_env\lib\site-packages\torch\nn\modules\module.py", line 1497, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for DataParallel:
size mismatch for module.Prediction.weight: copying a param with shape torch.Size([1009, 256]) from checkpoint, the shape in current model is torch.Size([1011, 256]).
size mismatch for module.Prediction.bias: copying a param with shape torch.Size([1009]) from checkpoint, the shape in current model is torch.Size([1011]).에러 해결
해결법을 찾느라 고생 좀 했다
deep-text-recognition-benchmark 프로젝트의 'train.py' 파일 수정
* character = 개수만 맞으면 정상 동작하는듯 하다. (추후에 학습할 글자를 디테일하게 설정 가능할듯?)
#easyocr -> config.py중 korean_g2의 characters 추가 (모델 설정 맞추기)
opt.character = " !\"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~가각간갇갈감갑값강갖같갚갛개객걀거걱건걷걸검겁것겉게겨격겪견결겹경곁계고곡곤곧골곰곱곳공과관광괜괴굉교구국군굳굴굵굶굽궁권귀규균그극근글긁금급긋긍기긴길김깅깊까깎깐깔깜깝깥깨꺼꺾껍껏껑께껴꼬꼭꼴꼼꼽꽂꽃꽉꽤꾸꿀꿈뀌끄끈끊끌끓끔끗끝끼낌나낙낚난날낡남납낫낭낮낯낱낳내냄냉냐냥너넉널넓넘넣네넥넷녀녁년념녕노녹논놀놈농높놓놔뇌뇨누눈눕뉘뉴늄느늑는늘늙능늦늬니닐님다닥닦단닫달닭닮담답닷당닿대댁댐더덕던덜덤덥덧덩덮데델도독돈돌돕동돼되된두둑둘둠둡둥뒤뒷드득든듣들듬듭듯등디딩딪따딱딴딸땀땅때땜떠떡떤떨떻떼또똑뚜뚫뚱뛰뜨뜩뜯뜰뜻띄라락란람랍랑랗래랜램랫략량러럭런럴럼럽럿렁렇레렉렌려력련렬렵령례로록론롬롭롯료루룩룹룻뤄류륙률륭르른름릇릎리릭린림립릿마막만많말맑맘맙맛망맞맡맣매맥맨맵맺머먹먼멀멈멋멍멎메멘멩며면멸명몇모목몰몸몹못몽묘무묵묶문묻물뭄뭇뭐뭣므미민믿밀밉밌및밑바박밖반받발밝밟밤밥방밭배백뱀뱃뱉버번벌범법벗베벤벼벽변별볍병볕보복볶본볼봄봇봉뵈뵙부북분불붉붐붓붕붙뷰브블비빌빗빚빛빠빨빵빼뺨뻐뻔뻗뼈뽑뿌뿐쁘쁨사삭산살삶삼상새색샌생서석섞선설섬섭섯성세센셈셋션소속손솔솜솟송솥쇄쇠쇼수숙순술숨숫숲쉬쉽슈스슨슬슴습슷승시식신싣실싫심십싱싶싸싹쌀쌍쌓써썩썰썹쎄쏘쏟쑤쓰쓸씀씌씨씩씬씹씻아악안앉않알앓암압앗앙앞애액야약얇양얗얘어억언얹얻얼엄업없엇엉엌엎에엔엘여역연열엷염엽엿영옆예옛오옥온올옮옳옷와완왕왜왠외왼요욕용우욱운울움웃웅워원월웨웬위윗유육율으윽은을음응의이익인일읽잃임입잇있잊잎자작잔잖잘잠잡장잦재쟁저적전절젊점접젓정젖제젠젯져조족존졸좀좁종좋좌죄주죽준줄줌줍중쥐즈즉즌즐즘증지직진질짐집짓징짙짚짜짝짧째쨌쩌쩍쩐쪽쫓쭈쭉찌찍찢차착찬찮찰참창찾채책챔챙처척천철첫청체쳐초촉촌총촬최추축춘출춤춥춧충취츠측츰층치칙친칠침칭카칸칼캐캠커컨컬컴컵컷켓켜코콜콤콩쾌쿠퀴크큰클큼키킬타탁탄탈탑탓탕태택탤터턱털텅테텍텔템토톤톱통퇴투툼퉁튀튜트특튼튿틀틈티틱팀팅파팎판팔패팩팬퍼퍽페펴편펼평폐포폭표푸푹풀품풍퓨프플픔피픽필핏핑하학한할함합항해핵핸햄햇행향허헌험헤헬혀현혈협형혜호혹혼홀홍화확환활황회획횟효후훈훌훔훨휘휴흉흐흑흔흘흙흡흥흩희흰히힘"수정 후 train.py 실행
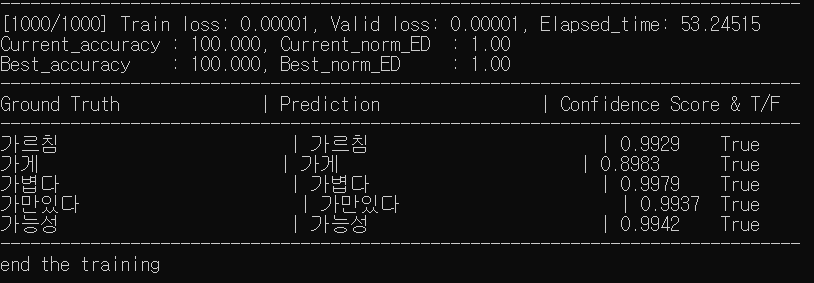
4. 학습 결과 확인
'deep-text-recognition-benchmark/saved_models/None-VGG-BiLSTM-CTC-Seed1111'에서 학습로그와 학습한 모델을 확인할 수 있다.
학습 모델 : best_accuracy.pth, best_norm_ED.pth
학습 로그 : log_dataset.txt, log_train.txt, opt.txt

5. 모델 적용 및 테스트
환경 구성은 이전 포스팅과 같다.
학습한 모델을 'EasyOCR/model' 위치로 이동 후 custom.pth로 이름을 변경

'EasyOCR/user_network/custom.yaml' 수정
* 해당 설정은 학습한 모델 설정과 같아야한다.
network_params:
input_channel: 1
output_channel: 256
hidden_size: 256
imgH: 32
lang_list:
- 'ko'
character_list: " !\"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~가각간갇갈감갑값강갖같갚갛개객걀거걱건걷걸검겁것겉게겨격겪견결겹경곁계고곡곤곧골곰곱곳공과관광괜괴굉교구국군굳굴굵굶굽궁권귀규균그극근글긁금급긋긍기긴길김깅깊까깎깐깔깜깝깥깨꺼꺾껍껏껑께껴꼬꼭꼴꼼꼽꽂꽃꽉꽤꾸꿀꿈뀌끄끈끊끌끓끔끗끝끼낌나낙낚난날낡남납낫낭낮낯낱낳내냄냉냐냥너넉널넓넘넣네넥넷녀녁년념녕노녹논놀놈농높놓놔뇌뇨누눈눕뉘뉴늄느늑는늘늙능늦늬니닐님다닥닦단닫달닭닮담답닷당닿대댁댐더덕던덜덤덥덧덩덮데델도독돈돌돕동돼되된두둑둘둠둡둥뒤뒷드득든듣들듬듭듯등디딩딪따딱딴딸땀땅때땜떠떡떤떨떻떼또똑뚜뚫뚱뛰뜨뜩뜯뜰뜻띄라락란람랍랑랗래랜램랫략량러럭런럴럼럽럿렁렇레렉렌려력련렬렵령례로록론롬롭롯료루룩룹룻뤄류륙률륭르른름릇릎리릭린림립릿마막만많말맑맘맙맛망맞맡맣매맥맨맵맺머먹먼멀멈멋멍멎메멘멩며면멸명몇모목몰몸몹못몽묘무묵묶문묻물뭄뭇뭐뭣므미민믿밀밉밌및밑바박밖반받발밝밟밤밥방밭배백뱀뱃뱉버번벌범법벗베벤벼벽변별볍병볕보복볶본볼봄봇봉뵈뵙부북분불붉붐붓붕붙뷰브블비빌빗빚빛빠빨빵빼뺨뻐뻔뻗뼈뽑뿌뿐쁘쁨사삭산살삶삼상새색샌생서석섞선설섬섭섯성세센셈셋션소속손솔솜솟송솥쇄쇠쇼수숙순술숨숫숲쉬쉽슈스슨슬슴습슷승시식신싣실싫심십싱싶싸싹쌀쌍쌓써썩썰썹쎄쏘쏟쑤쓰쓸씀씌씨씩씬씹씻아악안앉않알앓암압앗앙앞애액야약얇양얗얘어억언얹얻얼엄업없엇엉엌엎에엔엘여역연열엷염엽엿영옆예옛오옥온올옮옳옷와완왕왜왠외왼요욕용우욱운울움웃웅워원월웨웬위윗유육율으윽은을음응의이익인일읽잃임입잇있잊잎자작잔잖잘잠잡장잦재쟁저적전절젊점접젓정젖제젠젯져조족존졸좀좁종좋좌죄주죽준줄줌줍중쥐즈즉즌즐즘증지직진질짐집짓징짙짚짜짝짧째쨌쩌쩍쩐쪽쫓쭈쭉찌찍찢차착찬찮찰참창찾채책챔챙처척천철첫청체쳐초촉촌총촬최추축춘출춤춥춧충취츠측츰층치칙친칠침칭카칸칼캐캠커컨컬컴컵컷켓켜코콜콤콩쾌쿠퀴크큰클큼키킬타탁탄탈탑탓탕태택탤터턱털텅테텍텔템토톤톱통퇴투툼퉁튀튜트특튼튿틀틈티틱팀팅파팎판팔패팩팬퍼퍽페펴편펼평폐포폭표푸푹풀품풍퓨프플픔피픽필핏핑하학한할함합항해핵핸햄햇행향허헌험헤헬혀현혈협형혜호혹혼홀홍화확환활황회획횟효후훈훌훔훨휘휴흉흐흑흔흘흙흡흥흩희흰히힘"모델 테스트
EasyOCR의 run.py 실행
python run.py6. 결과

학습데이터와 학습횟수가 충분하지 않았음에도 생각보다 좋은 결과가 나온듯 하다.
신뢰성이 낮은 단어를 학습 시키면 더욱 좋은 결과가 나올 것으로 예상된다.
참고 사이트 : https://davelogs.tistory.com/94
'Python' 카테고리의 다른 글
| [Python] easyocr 사용자 모델 학습하기 - 학습 모델 테스트 (0) | 2022.07.15 |
|---|---|
| [Python] easyocr 사용자 모델 학습하기 - 모델 학습 (2) | 2022.07.14 |
| [Python] easyocr 사용자 모델 학습하기 - 학습데이터 변환 (0) | 2022.07.13 |
| [Python] easyocr 사용자 모델 학습하기 - 학습데이터 생성 (0) | 2022.07.12 |
| [python] multiprocessing (Pool) (0) | 2022.07.08 |



